| Issue |
Security and Safety
Volume 4, 2025
|
|
|---|---|---|
| Article Number | 2024023 | |
| Number of page(s) | 15 | |
| Section | Software Engineering | |
| DOI | https://doi.org/10.1051/sands/2024023 | |
| Published online | 23 July 2025 | |
Research Article
Finding Bayesian Nash equilibrium in DHR
1
School of Data Science, Fudan University, Shanghai, 200437, China
2
School of Computer Science, Fudan University, Shanghai, 200433, China
3
Institute of BigData, Fudan University, Shanghai, 200437, China
4
Purple Mountain Laboratories, Nanjing, 211111, China
* Corresponding author (email: This email address is being protected from spambots. You need JavaScript enabled to view it.
)
Received:
11
May
2024
Revised:
18
November
2025
Accepted:
19
December
2024
Abstract
This study presents an effective cybersecurity defense mechanism by integrating the Dynamic Heterogeneous Redundancy (DHR) architecture with advanced algorithmic strategies to combat complex, evolving cyber threats while maintaining system performance and cost efficiency. Experimental results demonstrate that, particularly through Bayesian model-based attack-defense simulations, our scheduling strategy adapts swiftly to dynamically changing attack-defense environments. It effectively selects combinations of heterogeneous executors that meet both performance and economic requirements, thereby achieving a Bayesian Nash equilibrium. The findings not only validate our research hypothesis and methodology but also offer new perspectives and tools for advancing future cybersecurity defenses. This contribution enhances the theoretical foundation for constructing endogenous security intelligence methods and provides practical solutions, marking a significant advancement in cybersecurity, particularly in the application of dynamic heterogeneous redundancy technologies.
Key words: DHR / Bayesian Nash / Reinforcement learning
Citation: Wu Y, Liu Y, and Chen P. Finding Bayesian Nash equilibrium in DHR. Security and Safety 2025; 4: 2024023. https://doi.org/10.1051/sands/2024023
© The Author(s) 2025. Published by EDP Sciences and China Science Publishing & Media Ltd.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1. Introduction
Reinforcement learning has shown success in finding optimal control strategies for single agents operating in static environments by balancing exploration and exploitation (EvE) to achieve optimal strategies. In the Adversarial Bandit Problem [1], where reward sequences vary unpredictably, the player must both explore to find the best possible choice and exploit known choices to maximize cumulative rewards. However, when facing an intelligent and adaptive opponent, as in adversarial scenarios, the environment becomes dynamic rather than static. Here, the opponent may change strategies in response to the player’s actions, leading to a constantly evolving environment that complicates the process of finding optimal solutions.
This dynamic, adversarial setting introduces a strategic interaction that can be framed as a game. Game theory [2, 3] provides insights for selecting optimal actions under such conditions, where both sides continuously adapt to each other’s moves. In this framework, the exploration-exploitation dynamic becomes a strategy game, where players (or algorithms) make sequential decisions in an environment where outcomes depend on the choices of both parties. Specifically, in adversarial Bandit problems, the unpredictable reward sequence requires the player to make optimal choices without complete information. Each decision thus becomes a complex process involving both adaptation to the opponent’s potential strategies and responses to the current state of the environment.
Game theory offers valuable tools, such as equilibrium analysis [4, 5], countermeasure strategies, and information asymmetry analysis, which help address common issues like overfitting or misfitting that may arise in reinforcement learning. By integrating these theoretical approaches, reinforcement learning can better handle the challenges of adversarial, dynamically changing environments, achieving robust solutions even under competitive conditions.
In this paper, we establish a cyber attack-defense game scenario to construct a Bayesian Nash equilibrium [6] model, where both the attacker and defender leverage historical data to iteratively adjust their strategies, enhancing their respective effectiveness. The defender applies Bayesian strategies to infer possible attack patterns and tactics that the attacker might employ, despite having limited information. This inference relies on a probabilistic model that considers various potential attack strategies and their respective probabilities, thereby approximating a state close to complete information.
To determine the optimal defense strategy, this study employs the EXP3 algorithm, enabling continuous learning and adaptation. Within the reinforcement learning framework, the defense system functions as an intelligent agent that learns to make optimal decisions by interacting with its environment. Following each attack, the system assesses the effectiveness of its defenses, adjusting its strategy by reinforcing or discouraging specific actions. This adaptive approach enables the defender to maximize the efficient use of resources while maintaining a robust security posture.
By implementing these strategies, cybersecurity systems not only adapt to the current dynamics of attack and defense but also anticipate and prepare for future threats. This allows them to stay one step ahead in complex, information-limited environments, enhancing resilience against evolving threats.
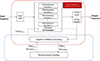 |
Figure 1. Bayesian Nash equilibrium with reinforcement learning algorithm in feedback scheduling module of DHR |
2. Related work
2.1. DHR
As shown in Figure 1, the Dynamic Heterogeneous Redundancy (DHR) architecture [7] is an implementation of the Mimic Defense strategy, designed to enhance security by constructing N functionally equivalent heterogeneous executables. This redundancy mitigates vulnerabilities that might be exploited within a single executable. Unlike Moving Target Defense (MTD) [8], DHR offers superior security and efficiency with respect to unit use and redundancy. Furthermore, DHR incorporates a feedback scheduling module that, coupled with its dynamic adaptability, enables robust defenses against both known and unknown attack vectors.
The feedback scheduling module in the DHR architecture operates on the basis of feedback scheduling informed by adjudication results from multiple heterogeneous executables. This mechanism facilitates the replacement of executables identified as potentially compromised. A crucial aspect of this process is maintaining a balance between system overhead and security, a challenge that requires careful attention. Consequently, the development of intelligent scheduling algorithms is a key research area within the DHR framework, aiming to optimize this balance and enhance overall system resilience.
2.2. Game theory
Game theory is a mathematical framework for analyzing how rational decision-makers, referred to as “players”, make decisions in situations involving conflicting interests. In a game, multiple players interact and may reach a Nash equilibrium through repeated interactions. Multi-player games are typically classified into discrete and continuous games: in discrete games, each player has a finite set of possible actions, while in continuous games, this set is infinite.
In many practical applications, players often have only limited information about the game. For example, each player might not know the exact structure of their own utility function [9], and during repeated interactions, they may also lack awareness of other players’ behaviors. These informational constraints have motivated research into gain-based or reinforcement learning algorithms, where players adjust their strategies based solely on their own past actions and utility outcomes. For instance, the algorithm presented in [2] finds the Nash equilibrium of a weakly acyclic game with high probability by using a pre-set, arbitrarily small rate of exploration.
The Bayesian Nash Equilibrium (BNE) [3–6] extends the Nash Equilibrium concept to scenarios where players have incomplete information about each other. In BNE, each player does not fully know the other players’ payoffs, strategies, or types. Instead, they hold probabilistic beliefs about the types of other players, where a “type” represents characteristics, preferences, or private information that can influence strategic decisions.
2.3. Adversarial bandit problem
In numerous machine learning scenarios, particularly those characterized by adversarial settings, the traditional assumptions about reward sequences provided by experts are often disregarded, as these reward sequences are considered arbitrary, following the framework presented in [1].
In such environments, at each time step t, the agent has access only to the rewards accumulated up to the previous time step, denoted as 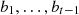 . To evaluate the agent’s performance, the concept of adversarial regret is used, comparing the agent’s cumulative reward to that of the best fixed strategy over time. Adversarial regret is defined as the difference between the cumulative reward of the best fixed expert across all time steps,
. To evaluate the agent’s performance, the concept of adversarial regret is used, comparing the agent’s cumulative reward to that of the best fixed strategy over time. Adversarial regret is defined as the difference between the cumulative reward of the best fixed expert across all time steps, 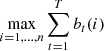 , and the cumulative reward of the algorithm is currently in use.
, and the cumulative reward of the algorithm is currently in use.
The primary goal in this adversarial framework is to minimize the expected adversarial regret across all possible reward sequences 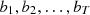 . This approach ensures robustness by benchmarking the algorithm’s performance against the optimal fixed expert strategy, regardless of the complexity or unpredictability of the encountered reward sequence.
. This approach ensures robustness by benchmarking the algorithm’s performance against the optimal fixed expert strategy, regardless of the complexity or unpredictability of the encountered reward sequence.
2.4. Reinforcement learning algorithms
In adversarial scenarios, the attacker’s sequence of attacks is uncertain, prompting the application of the Adversarial Expert Problem framework to optimize the defender’s gains. Auer [10] introduces the EXP3 algorithm, which balances exploration and exploitation to address challenges in adversarial environments. Additionally, [11] extends the work of Auer et al. on adversarial multi-armed bandit problems by proposing and analyzing a new algorithm, Exp3.M, designed to solve the problem of selecting multiple actions at each time step. This algorithm demonstrates superior time and space complexities compared to existing algorithms. Slivkins [12] further improves on these approaches by enhancing exploration efficiency in environments characterized by gradual changes in costs.
2.5. Integration of game theory and reinforcement learning
Marc Lanctot et al. [13]. propose a novel Multi-Agent Reinforcement Learning (MARL) meta-algorithm that generates a mixture of strategies using deep reinforcement learning, combined with empirical game-theoretic analysis to compute a meta-strategy for selecting optimal strategies. This approach effectively mitigates the overfitting issues commonly encountered in stand-alone reinforcement learning and demonstrates the adaptability of strategies across a wide range of partially-observable environments.
Littman extends the traditional MDP Q-Learning algorithm to zero-sum stochastic games by modifying the value function to preserve the value of joint actions and replacing the standard “max” operation with the “Value” operator, allowing the approach to address multi-agent environments.
The fictitious play algorithm operates under the assumption that opponents use static strategies. It identifies the historically best-performing action based on the average utility of each action. When all players adopt fictitious play, the algorithm converges to a Nash equilibrium in iteratively dominant solvable games or fully cooperative games. Additionally, in zero-sum games, it enables the identification of equilibrium strategies and supports mixed equilibrium strategies by smoothing the virtual matchmaking process.
3. Overall design
The proposed approach integrates Bayesian processes with reinforcement learning to create a robust and adaptive defense mechanism tailored to dynamic attack-defense scenarios (DHR). This section outlines the underlying design philosophy, emphasizing why Bayesian processes and reinforcement learning were chosen and how their integration addresses the challenges inherent in cybersecurity.
3.1. Motivation for using bayesian processes
Bayesian processes provide a powerful framework for reasoning under uncertainty, which is critical in dynamic attack-defense scenarios where defenders operate with incomplete or imperfect information. In such environments, Bayesian methods enable the defender to:
-
(1)
Incorporate prior knowledge: By leveraging prior distributions, Bayesian processes allow the defender to initialize the system with domain knowledge or historical data. This ensures that even in the absence of significant real-time data, the system has a meaningful starting point for decision-making.
-
(2)
Update beliefs dynamically: As new observations are collected, Bayesian inference dynamically updates the defender’s beliefs about the attacker’s strategies, improving the accuracy of predictions over time. This adaptability is essential in rapidly evolving attack scenarios.
-
(3)
Support probabilistic decision-making: The probabilistic nature of Bayesian methods provides a formal mechanism for quantifying uncertainty, which is invaluable when evaluating and comparing potential defensive actions under varying levels of risk.
3.2. Motivation for reinforcement learning integration
While Bayesian processes excel at handling uncertainty, they rely on prior distributions and can struggle to adapt quickly to highly dynamic and previously unseen conditions. Reinforcement learning (RL), particularly algorithms like EXP3, complements Bayesian processes by introducing the following capabilities:
-
(1)
Adaptation through exploration and exploitation: RL algorithms dynamically learn optimal strategies by balancing exploration (trying new actions to discover their utility) and exploitation (focusing on actions known to perform well). This enables the defender to continuously improve their strategies in response to the attacker’s evolving behavior.
-
(2)
Online learning in dynamic environments: Unlike static Bayesian updates, RL can adapt strategies in real-time based on direct interaction with the environment, making it well-suited for highly dynamic attack-defense interactions.
-
(3)
Scalability to complex action spaces: RL methods like EXP3 are designed to handle large or complex action spaces efficiently, enabling the defender to optimize resource allocation and scheduling in heterogeneous systems.
3.3. Rationale for integration
The integration of Bayesian processes and reinforcement learning leverages the strengths of both approaches, creating a hybrid mechanism that addresses the limitations of each individually. The rationale for this integration is as follows:
-
(1)
Complementary strengths: Bayesian processes provide a principled starting point through prior knowledge and probabilistic reasoning, while reinforcement learning introduces adaptability and resilience in dynamic, uncertain environments. Together, they create a system capable of both long-term stability and short-term responsiveness.
-
(2)
Handling uncertainty and dynamism: In the early stages of a defense scenario, Bayesian methods guide the initial strategy selection based on prior knowledge, reducing the risk of arbitrary or suboptimal decisions. As the interaction evolves and more data becomes available, reinforcement learning progressively refines these strategies, ensuring that the system adapts to real-time conditions.
-
(3)
Improved convergence and performance: By combining the probabilistic rigor of Bayesian inference with the exploratory capabilities of RL, the system achieves better convergence properties and performance in scenarios where either approach alone might struggle.
4. Problem formulation
4.1. Reinforcement learning in DHR
In this section, we introduce the EXP3 [14–18] DHR model, adapted for adversarial environments. We consider N units, from which M units are selected to form a total of 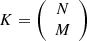 heterogeneous executors. In each round t, a specific combination i is selected and deployed in the defense pool. We assume a total of T rounds of attacks, with each round involving a random attack targeting the current combination of units in the pool.
heterogeneous executors. In each round t, a specific combination i is selected and deployed in the defense pool. We assume a total of T rounds of attacks, with each round involving a random attack targeting the current combination of units in the pool.
The effectiveness of each unit j during an attack in round t is quantified by a utility metric, denoted as 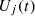 . This utility is calculated as:
. This utility is calculated as:
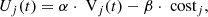
where 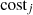 represents the energy cost associated with operating each unit, and
represents the energy cost associated with operating each unit, and 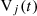 measures the efficacy of unit j in countering the attack. The parameters α and β serve as weights to indicate the relative importance of performance and cost, respectively. The range of
measures the efficacy of unit j in countering the attack. The parameters α and β serve as weights to indicate the relative importance of performance and cost, respectively. The range of 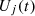 is normalized to [0,1].
is normalized to [0,1].
The performance of the selected unit combination it in round t is given by:
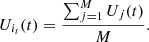
If a specific unit j consistently receives a low reward 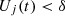 in round t, this pattern suggests that external attacks may be targeting this unit combination with a fixed strategy, analogous to the observed reward pattern in round t.
in round t, this pattern suggests that external attacks may be targeting this unit combination with a fixed strategy, analogous to the observed reward pattern in round t.
The central objective is to develop a defense strategy that optimally mitigates the impact of these attacks. To achieve this, we employ the concept of expected regret, which measures the expected difference between the performance of the optimal strategy and the current defense strategy over T rounds.
Input: Costs, number of iterations, learning rate γ
Output: Optimal combination of executors
1: Initialize:
2: Performance history ← Matrixiterations × N
3: Weights wi = 1 for i = 1; … N
4: Learning rate 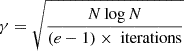
5: for t = 1; … iterations do
6: Calculate probabilities:
7: 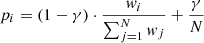
8: Choose an executor xit based on probabilities pi
9: Observe reward rit for chosen xit
10: Update weights:
11: 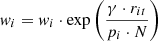
12: end for
13: Determine optimal executors by analyzing Performance History
4.2. Bayesian Nash equilibrium in DHR
In the preceding section, we simplified our assumptions concerning the attacker, who was presumed to make random attacks with minimal utilization of feedback information. This simplification represents a significant departure from realistic adversarial scenarios, where information asymmetry and incompleteness prevail between attackers and defenders. Both parties are motivated to optimize their strategies based on available information to maximize their respective gains.
The adversarial process is modeled using the Bayesian Nash framework, as referenced in literature [3, 4, 17, 18]. Within this model, both attackers and defenders dynamically adjust their strategies based on the outcomes of previous rounds of attacks and defenses. Specifically, the EXP3 algorithm is implemented as the defensive strategy, while the attacker adjusts their tactics based on limited feedback information. The attacker possesses m attack methods across various states, with differential probabilities of employing each method depending on the state. This allows the attacker to adapt their state based on feedback to optimize attack outcomes.
Defensively, we consider N units from which M units are selected to form a total of 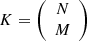 heterogeneous actuators. A Bayesian model updates the posterior probabilities of the attacker utilizing one of the m attack methods. This update is based on observed attack patterns, and the expected defensive utility is calculated accordingly. The EXP3 algorithm selects the most effective heterogeneous actuator based on this expected utility for deployment against attacks.
heterogeneous actuators. A Bayesian model updates the posterior probabilities of the attacker utilizing one of the m attack methods. This update is based on observed attack patterns, and the expected defensive utility is calculated accordingly. The EXP3 algorithm selects the most effective heterogeneous actuator based on this expected utility for deployment against attacks.
Given the asymmetric and incomplete information landscape, the concept of Bayesian Nash equilibrium is extensively applied. Using available feedback, the equilibrium seeks to find optimal strategies for both parties where each strategy is the best response considering the opponent’s strategy.
Assuming the attacker’s strategy space 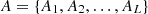 and the state space
and the state space 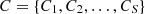 , the probability of selecting attacks from A varies across states. The attack-state probability matrix
, the probability of selecting attacks from A varies across states. The attack-state probability matrix 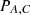 delineates these probabilities. If K heterogeneous actuators are formed from N heterogeneous units, with each actuator containing M units, the feedback from an attack can be binary (0 or 1). Consistent feedback from all M units within an actuator, either all 0s or all 1s, indicates stability with a higher defense gain (v1). In contrast, inconsistent feedback suggests chaos within the actuator, resulting in a lower defense gain (v2, where
delineates these probabilities. If K heterogeneous actuators are formed from N heterogeneous units, with each actuator containing M units, the feedback from an attack can be binary (0 or 1). Consistent feedback from all M units within an actuator, either all 0s or all 1s, indicates stability with a higher defense gain (v1). In contrast, inconsistent feedback suggests chaos within the actuator, resulting in a lower defense gain (v2, where 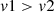 ). There remains a probability Pn that an actuator with consistent feedback erroneously reports a v2 outcome.
). There remains a probability Pn that an actuator with consistent feedback erroneously reports a v2 outcome.
In scenarios of information asymmetry, after each attack, the attacker learns whether the heterogeneous actuators’ feedback was consistent (rt), with rt taking values 0 or 1. The empirical average feedback RT indicates the attack’s impact over T rounds, which is calculated as:
![Mathematical equation: $$ \begin{aligned} R_T = \sum \frac{r_t}{T} \quad \quad R_T \in [0,1] \end{aligned} $$](/articles/sands/full_html/2025/01/sands20240010/sands20240010-eq56.gif)
informs the attacker’s decisions. ϵ is a hyper parameter to determine whether the attack is effective, If 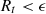 , the attacker may choose a new state from their state space for subsequent attacks, resetting Rt. Each round, the defender perceives the attack method
, the attacker may choose a new state from their state space for subsequent attacks, resetting Rt. Each round, the defender perceives the attack method 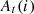 used by the attacker, evaluates the defense gain based on the feedback rt, and calculates the defense utility
used by the attacker, evaluates the defense gain based on the feedback rt, and calculates the defense utility 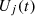 for each heterogeneous executor,as the difference between the defense gain
for each heterogeneous executor,as the difference between the defense gain 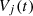 and the execution
and the execution 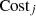 . The Bayesian model, updated with the known attack methods, aids in estimating the expected defense utility for the next round for each executor,
. The Bayesian model, updated with the known attack methods, aids in estimating the expected defense utility for the next round for each executor, 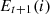 . The EXP3 algorithm then selects an appropriate heterogeneous executor to counter the next attack based on the estimated utilities.
. The EXP3 algorithm then selects an appropriate heterogeneous executor to counter the next attack based on the estimated utilities.
Input: ∊∈ [0, 1]
1: Initialize: the attacker’s initial attack state probability space Pc, the attack-mode-state probability matrix PA–c, the defender’s probability estimate for attack j, P(Aj) = 1/L (where L is the size of the attack space A).
2: for t = 1, 2, … do
3: Choose Atj by probabilities PA–c
4: Expected utility Et(i): 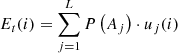
5: Execute EXP3 algorithm, get reward Rt
6: Update the attacker’s attack state:
7: if Rt < ∊ then
8: The attacker randomly transitions to the remaining attack state
9: end if
10: The defender’s probability estimate for attack i, P(Aj): 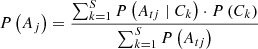
11: Update P(Aj) · P(Ai | Ck)
12: end for
5. Experiment
5.1. Design Overview and Experiment Motivation
The experiments are designed to validate the integrated approach of Bayesian processes and reinforcement learning, reflecting the core design philosophy. Specifically, the following aspects were tested:
- (1)
Bayesian initialization: Defensive strategies are initialized using prior knowledge modeled through Bayesian processes, ensuring that early-stage decisions are grounded in meaningful assumptions even with limited observational data.
- (2)
Reinforcement learning for adaptation: The EXP3 algorithm dynamically adapts defensive strategies based on real-time feedback, balancing exploration and exploitation to handle changes in the attack environment effectively.
- (3)
Dynamic attack-defense interactions: Simulated attack-defense scenarios evaluate the system’s ability to adapt under uncertainty, maintain stability, and achieve optimal
5.2. Reinforcement learning in DHR
5.2.1. Initialization
The code begins by defining the costs for 10 heterogeneous units, with each cost value ranging from 0 to 1, representing the level of investment in each unit. Performance simulation is achieved through a stochastic probabilistic process, where the performance of each unit is modeled using a normal distribution. Specifically, each unit’s performance is simulated according to a normal distribution with the unit’s cost as the mean and a variance of 0.01 (i.e., one percent of the full cost range). Higher-cost units are thus designed to have a higher probability of superior performance, representing the potential benefits of increased security investments.
 |
Figure 2. Performance dynamics of operational units over iterations, illustrating the changes in unit performance (U) as time progresses under varying costs. |
Performance simulation is conducted through a stochastic probabilistic process in which each unit’s performance is modeled according to a normal distribution, adjusted based on its cost. Specifically, each unit’s performance follows a normal distribution where the cost serves as the mean and the variance is set to 0.01 (equivalent to one hundredth of a percent of the cost range 1), as illustrated in Figure 2. This design ensures that higher-cost units have a higher probability of exhibiting superior performance, effectively modeling the potential advantages of higher security investments.
Additionally, a penalty mechanism is introduced to simulate performance degradation following a security breach, demonstrating the adverse effects of security incidents on a unit’s operational effectiveness. The probability of a breach is positively correlated with the unit’s cost, as shown in Figure 3.
 |
Figure 3. Performance dynamics of operational units over iterations under penalty conditions, showing the impact of penalties on unit performance (U) as time progresses with varying costs. |
5.2.2. EXP3 algorithm
The core of the EXP3 algorithm lies in dynamically selecting the best-performing combination of units in each iteration to maximize overall performance. In our experimental setup, the defense system is configured to select 4 out of 10 units, resulting in a total of 210 possible combinations based on probabilistic combinatorial analysis.
The algorithm achieves optimization by maintaining a weights_history list, where each unit’s weight directly influences the probability of its selection in the next iteration. In each iteration, the algorithm calculates the probability of selecting each unit based on the current weights and then forms a combination of units according to these probabilities. By evaluating the performance of the selected combination and updating the weights based on performance feedback, the algorithm adaptively optimizes the unit selection strategy over time.
Weight updating is a key aspect of the EXP3 algorithm, driven by each unit’s performance relative to its selection probability. If a unit performs well, its weight increases, thereby raising its probability of being selected in subsequent iterations. This update mechanism promotes a balance between exploration (trying different unit combinations) and exploitation (selecting units known to perform well), enabling the algorithm to seek optimal solutions within an uncertain environment.
During the simulation, a penalty mechanism is introduced by temporarily degrading the performance of compromised units, as shown in Figure 3. This mechanism simulates the immediate impact of security breaches on unit performance and influences the algorithm’s selection preferences. By reducing the likelihood of selecting recently compromised units in future iterations, the algorithm becomes more adaptable to security threats, enhancing the system’s resilience to evolving security challenges.
5.3. Bayesian Nash equilibrium in DHR
5.3.1. Attack hypothesis
To address the limitations of previous assumptions, where the cost and performance of each unit were overly correlated, we introduce new assumptions regarding attack patterns and unit behavior:
Define the attacker as having 4 distinct attack patterns, 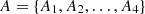 , and a set of attack strategies
, and a set of attack strategies 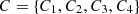 . Let
. Let 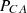 represent the probability space associated with the attacker’s strategy for each attack pattern as shown in Table 1.
represent the probability space associated with the attacker’s strategy for each attack pattern as shown in Table 1.
Probability of attack space
-
(1)
Assume that the order of different attacks has some correlation and coherence, which is shown by the fact that after different attacks, the probability of what kind of attack is next will be adjusted with the previous attacks.
-
(2)
Assume that different isoforms respond differently to different attacks, i.e. the same isoform will respond differently to different attacks.
5.3.2. Defend hypothesis
The code begins by defining the cost for 10 heterogeneous units, with each cost ranging from 0 to 1, representing the level of investment in each unit. Performance simulation is achieved through a stochastic probabilistic process in which each unit’s performance is modeled according to a normal distribution. Specifically, each unit’s performance follows a normal distribution where the cost serves as the mean and the variance is set to 0.01 (i.e., one percent of the cost range).
Each unit exhibits a different defensive effectiveness against the same type of attack, reflected in varying probabilities of successfully defending against the attacker’s strategy. Given an attacker with 4 possible attack types, 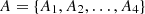 , the success matrix S represents the defense outcomes for different units, defined as
, the success matrix S represents the defense outcomes for different units, defined as 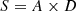 , where D denotes the executors in the executor pool, as shown in Table 2.
, where D denotes the executors in the executor pool, as shown in Table 2.
S matrix
The defence gain v1 for a successful defence of a heterogeneous executor is 1, and the defence gain v2 for a failed defence is 0. The defender’s assumption about the attacker’s initial attack state space C = 0.4, 0.3, 0.2, 0.1. The attacker’s state-attack probability space 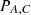 . Defenders use EXP3 defence strategy and expectation-maximisation defence strategy during the defence process to compare the results, respectively.
. Defenders use EXP3 defence strategy and expectation-maximisation defence strategy during the defence process to compare the results, respectively.
The experimental results preliminary show that the Bayesian Nash attack and defence model can effectively simulate the use and derivation of attack and defence information by both attackers and defenders in the DHR architecture, and dynamically arrive at the (locally stable) optimal choices by combining different strategy selection algorithms, presenting a double-blind effect.
6. Results
6.1. Randomised attack environment
In a randomised attack environment, it is assumed that the attacker’s strategy remains relatively stable and follows a consistent distribution. We compare the executor selection performance of the EXP3 algorithm against a random selection strategy. In the EXP3 strategy, unit selection is guided by performance weights, reflecting the impact of historical performance on current selection choices. Conversely, the random strategy disregards historical performance entirely, assigning each unit an equal probability of selection.
As shown in Figure 4, experimental results indicate that the EXP3 algorithm outperforms the random selection strategy. This advantage can be attributed to the exploration and exploitation mechanism of the EXP3 algorithm, which effectively balances historical performance data with new selection opportunities. These findings suggest that algorithms incorporating historical performance data can achieve more stable and reliable outcomes in uncertain and dynamic environments.
 |
Figure 4. Heatmap of unit selection frequency over iterations using the EXP3 algorithm (left) and stochastic algorithm (right), highlighting adaptive selection in EXP3 versus random selection in the stochastic approach. |
As shown in Figure 3, further experiments were conducted to examine the impact of introducing penalty terms on the algorithm’s robustness. In scenarios with a penalty mechanism, the performance of penalized units are temporarily degraded to simulate the effects of a real-world security breach. We compare the performance of the EXP3 algorithm with and without this penalty mechanism. Specifically, in the algorithm, the highest-performing units are penalized from generation 9000 to generation 10500.
The results indicate that the EXP3 algorithm tends to overfit, struggling to move away from previously optimal choices when penalties are imposed on attacked heterogeneous units. This overfitting results in a delayed response to changes in the external attack environment, as the algorithm shows difficulty in adapting quickly to new security vulnerabilities and unknown threats.
6.2. Gaming environment
In this study, redesigned experiments were conducted to simulate unit selection under the attack hypothesis, comparing the performance of the EXP3 algorithm with a stochastic (random) selection algorithm. Analysis of the results reveals that the EXP3 algorithm demonstrates more stable and consistently trending performance in unit selection compared to the random selection strategy.
As a reinforcement learning algorithm, EXP3 can make effective decisions in uncertain environments by accumulating historical information and making probabilistic choices based on this data. In these experiments, the EXP3 algorithm leverages historical attack information and heterogeneous performance data to optimize its selection strategy, adjusting selection probabilities to enhance system security in response to successive attacks.
As shown in Figure 5, the random algorithm, although simple and easy to implement, lacks any utilization or analysis of historical information. This results in a selection process that is entirely random, showing no discernible trends or stability. When faced with continuous attacks, the random algorithm’s performance lacks specificity, which may compromise system defense effectiveness.
 |
Figure 5. Frequency of selection of different units over time using the EXP3 algorithm in a Bayesian environment, illustrating the dynamic adaptation of selection probabilities across iterations. |
7. Additional analysis
In dynamic attack-defense scenarios, defenders often rely on Bayesian methods to estimate incomplete information and use reinforcement learning algorithms, such as the adaptive EXP3 algorithm, to continuously adjust their strategies. While this combination is powerful, it also introduces significant challenges, particularly concerning non-convergence. Non-convergence occurs when the iterative updates of strategies fail to stabilize, leading to unpredictable or suboptimal outcomes. This issue becomes especially pronounced in dynamic and uncertain environments where early inaccuracies in learning or overly complex interactions amplify over time.
7.1. Key factors influencing convergence
Continuity and finiteness of the strategy space: The structure of the strategy space plays a critical role in determining whether convergence can be achieved. If the strategy spaces of both the attacker and defender are continuous and finite, there is a greater likelihood of stabilizing into a Bayesian Nash equilibrium. However, when the strategy space is large, highly dimensional, or effectively infinite, finding a stable equilibrium becomes significantly more complex. The exploration required in such spaces often exacerbates non-convergence, as reinforcement learning algorithms may oscillate between suboptimal strategies without stabilizing.
Availability and completeness of information: In the Bayesian framework, the ability of both parties to access and utilize information effectively is essential. When both the attacker and defender are fully rational and can accurately predict each other’s behavior, achieving equilibrium becomes feasible. However, in real-world scenarios, the information available to either party is often incomplete or inaccurate. This imperfect information, combined with bounded rationality or misjudgments, can result in strategy updates based on flawed assumptions, further increasing the likelihood of non-convergence.
Reinforcement learning for strategy updates: Reinforcement learning algorithms, like the EXP3 algorithm, dynamically adjust strategies by balancing exploration and exploitation. While this adaptability is beneficial, it also introduces potential instability. In the early stages of learning, inaccuracies in reward estimation or environmental modeling can result in suboptimal decisions. These early errors may propagate through subsequent iterations, leading to persistent oscillations or divergence from an optimal strategy. This problem becomes more acute in high-dimensional attack-defense environments, where the complexity of interactions increases the difficulty of learning stable strategies.
Influence of initial state and algorithmic strategy choice: In dynamic games, initial conditions and algorithmic design strongly influence long-term outcomes. Small variations in the starting conditions can result in widely divergent strategy paths, especially if the learning algorithm lacks robustness. However, strategies with strong self-correcting mechanisms–such as those leveraging convergence-guaranteed algorithms or hybrid models–can mitigate the impact of early-stage inaccuracies and promote stability over time.
7.2. Potential solutions to non-convergence
To address the challenge of non-convergence in dynamic attack-defense scenarios, we propose the following approaches:
-
(1)
Enhancing environmental modeling: The precision of environmental modeling is critical to reducing uncertainties that hinder convergence. Advanced techniques such as Gaussian Processes or Dynamic Bayesian Networks can provide more accurate representations of attack-defense dynamics. By offering better contextual information, these models enable reinforcement learning algorithms to stabilize more effectively in uncertain environments.
-
(2)
Adopting hybrid models: Combining Bayesian inference and reinforcement learning can alleviate non-convergence issues. For example, Bayesian methods can be used to initialize strategies with well-informed priors, while reinforcement learning gradually adapts to dynamic conditions. This hybrid approach minimizes the amplification of early inaccuracies and improves stability in later stages of learning.
-
(3)
Incorporating convergence-guaranteed optimization: Algorithms with proven convergence properties, such as those based on convex optimization or regularized policy gradients, can provide stability guarantees. These methods constrain the learning process, reducing oscillations and guiding the strategy updates toward equilibrium.
8. Conclusion
This study conducts an in-depth investigation into the construction methods of endogenous security intelligence, with a particular focus on the effective application of Dynamic Heterogeneous Redundancy (DHR) architecture in heterogeneous environments. Central to this research is the integration and efficient scheduling of heterogeneous units to counter complex and evolving cybersecurity threats, balancing performance with cost while considering the resilience of various combination configurations against continuously evolving attack strategies.
The combination and scheduling strategies of heterogeneous units are crucial for the successful implementation of the DHR architecture. The core strategy revolves around precisely selecting and configuring units to achieve an optimal balance between resisting diverse attacks and maintaining system operational efficiency and cost-effectiveness. To this end, the EXP3 algorithm, a reinforcement learning-based approach, is adopted to explore innovative scheduling algorithms for units. This algorithm optimizes the configuration of units by dynamically adapting to changing environments through continuous exploration and exploitation of available knowledge.
Moreover, given the complexity and uncertainty of the attack-defense environment, the study further investigates the impact of a Bayesian Nash equilibrium-based attack-defense model on DHR scheduling methods. By simulating attack-defense interactions, we gain deeper insights into how to deploy the DHR architecture against complex security threats under various initial assumptions. This game-theoretic approach not only aids in identifying and evaluating potential attack strategies but also guides the adjustment and optimization of defense strategies to enhance overall system security.
Experimental results demonstrate that by integrating the DHR architecture with reinforcement learning algorithms, especially under scenarios simulated based on Bayesian Nash equilibrium, our scheduling strategy quickly adapts to dynamically changing environments and effectively selects an executor combination that meets both performance requirements and economic efficiency. These findings not only validate our problem hypothesis and research methodology but also provide new perspectives and tools for future cybersecurity defenses. Collectively, this research illustrates an effective security defense mechanism by combining DHR architecture with advanced algorithmic strategies, successfully countering complex and variable cyber-attacks while ensuring system performance and cost-effectiveness.
9. Limitations and future work
While the proposed approach demonstrates significant advantages, certain limitations remain:
-
(1)
Overfitting in reinforcement learning: As observed in the randomised attack environment, the EXP3 algorithm occasionally struggles to adapt when penalties are introduced. Future work should explore algorithmic enhancements, such as regularized learning or hybrid models, to improve robustness against overfitting.
-
(2)
Delayed adaptation to abrupt changes: In dynamic gaming environments, reinforcement learning exhibited delays in responding to rapid changes in attack patterns. Incorporating faster adaptive mechanisms, such as meta-learning or contextual modeling, could address this issue.
-
(3)
Scalability to high-dimensional spaces: The current approach performs well in finite and moderately complex strategy spaces but may face challenges in large-scale, high-dimensional environments. Future research should investigate scalable techniques, such as hierarchical reinforcement learning or dimensionality reduction methods.
By addressing these limitations, the proposed framework can be further refined to handle more diverse and complex attack-defense scenarios effectively.
Acknowledgments
We thank all anonymous reviewers for their helpful comments and suggestions.
Funding
This work was supported by National Key R&D Program of China (2022YFB3102800).
Conflicts of interest
The authors declare that they have no conflict of interest.
Data availability statement
No data are associated with this article.
Author contribution statement
Yue Wu contributed to the framework design and the experiment design, serving as the first author. Yu Liu was involved in the manuscript writing and some experimental studies, as well as proofreading and editing the final paper. Prof. Chen also contributed to the framework design and editing the final paper, serving as the corresponding author.
References
- Cesa-Bianchi N, Lugosi G and Stoltz G. Regret minimization under partial monitoring. Math Oper Res 2006; 31: 562–580. [Google Scholar]
- Marden JR. State based potential games. Automatica 2012; 48: 3075–3088. [Google Scholar]
- Picheny V, Binois M and Habbal A. A Bayesian optimization approach to find Nash equilibria. J Glob Optim 2019; 73: 171–192. [Google Scholar]
- Bichler M, Fichtl M and Oberlechner M. Computing Bayes–Nash equilibrium strategies in auction games via simultaneous online dual averaging. Operat Res 2023; 73: 1102–1127. [Google Scholar]
- Wang Z, Shen W and Zuo S. Bayesian nash equilibrium in first-price auction with discrete value distributions. In: Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, 2020, 1458–1466. [Google Scholar]
- Ui T. Bayesian Nash equilibrium and variational inequalities. J Math Econ 2016; 63: 139–146. [Google Scholar]
- Wu JX. Cyberspace endogenous safety and security. Engineering 2021; 15: 179–185. [Google Scholar]
- Zhang XY and Li ZB. Overview on moving target defense technology. Commun Technol 2013; 46: 111–113 [Google Scholar]
- Hu Z, Chen P and Zhu M, et al. A co-design adaptive defense scheme with bounded security damages against Heartbleed-like attacks. IEEE Trans Inf Forens Secur 2021; 16: 4691–4704. [Google Scholar]
- Auer P, Cesa-Bianchi N and Freund Y, et al. The nonstochastic multiarmed bandit problem. SIAM J Comput 2002; 32: 48–77. [Google Scholar]
- Uchiya T, Nakamura A and Kudo M. Algorithms for Adversarial Bandit Problems with Multiple Plays Conference on Learning Theory. ALT 2010; 375–389. [Google Scholar]
- Seldin Y and Lugosi G. An improved parametrization and analysis of the EXP3++ algorithm for stochastic and adversarial bandits. Conference on Learning Theory, PMLR, 2017, 1743–1759. [Google Scholar]
- Lanctot M, Zambaldi V and Gruslys A, et al. A unified game-theoretic approach to multiagent reinforcement learning. Adv. Neural Inf Proc Syst 2017; 30. [Google Scholar]
- Gajane P, Urvoy T and Clérot F. A relative exponential weighing algorithm for adversarial utility-based dueling bandits. In: International Conference on Machine Learning, PMLR, 2015, 218–227. [Google Scholar]
- Bistritz I, Zhou Z and Chen X, et al. Online EXP3 learning in adversarial bandits with delayed feedback. Adv Neural Inf Proc Syst 2019; 32. [Google Scholar]
- Seldin Y, Szepesvári C and Auer P, et al. Evaluation and analysis of the performance of the EXP3 algorithm in stochastic environments. In: European Workshop on Reinforcement Learning, PMLR, 2013, 103–116. [Google Scholar]
- Allesiardo R and Féraud R. EXP3 with drift detection for the switching bandit problem. 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), IEEE, 2015, 1–7. [Google Scholar]
- Gutowski N, Amghar T and Camp O, et al. Gorthaur-EXP3: Bandit-based selection from a portfolio of recommendation algorithms balancing the accuracy-diversity dilemma. Inf Sci 2021; 546: 378–396. [Google Scholar]

Yue Wuis currently a Master’s student at Fudan University, China. Her main research interests include reinforcement learning and strategic game theory, agent system development, Retrieval-Augmented Generation, and graph algorithm.

Yu Liuis currently a Ph.D. student at Fudan University, China. His main research interests include software and system security, cyberspace endogenous security, and program analysis.

Pin Chen is currently a researcher at Fudan University, China. His main research interest include software and system security, cyberspace endogenous security, intelligent vehicle security, vulnerability discovery, blockchain security, and anti-fraud.
All Tables
All Figures
|
Figure 1. Bayesian Nash equilibrium with reinforcement learning algorithm in feedback scheduling module of DHR |
| In the text | |
|
Figure 2. Performance dynamics of operational units over iterations, illustrating the changes in unit performance (U) as time progresses under varying costs. |
| In the text | |
|
Figure 3. Performance dynamics of operational units over iterations under penalty conditions, showing the impact of penalties on unit performance (U) as time progresses with varying costs. |
| In the text | |
|
Figure 4. Heatmap of unit selection frequency over iterations using the EXP3 algorithm (left) and stochastic algorithm (right), highlighting adaptive selection in EXP3 versus random selection in the stochastic approach. |
| In the text | |
|
Figure 5. Frequency of selection of different units over time using the EXP3 algorithm in a Bayesian environment, illustrating the dynamic adaptation of selection probabilities across iterations. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.