| Issue |
Security and Safety
Volume 3, 2024
|
|
|---|---|---|
| Article Number | 2023028 | |
| Number of page(s) | 4 | |
| Section | Industrial Control | |
| DOI | https://doi.org/10.1051/sands/2023028 | |
| Published online | 23 January 2024 | |
Commentary
Optimal DoS attack on multi-channel cyber-physical systems: A Stackelberg game analysis
1
Department of Control Science and Engineering, Tongji University, Shanghai, 200092, China
2
Shanghai Research Institute for Intelligent Autonomous Systems, Shanghai, 201210, China
3
School of Information Science and Engineering, East China University of Science and Technology, Shanghai, 200237, China
* Corresponding author (email: zhang_hao@tongji.edu.cn)
Received:
17
March
2023
Revised:
19
June
2023
Accepted:
17
August
2023
Citation: Wang ZP, Shen H, Zhang H, Gao S and Yan H. Optimal DoS attack on multi-channel cyber-physical systems: A Stackelberg game analysis. Security and Safety 2024; 3: 2023028. https://doi.org/10.1051/sands/2023028
1. Problem formulation
1.1. System model and communication channel
Consider a simplified model of a cyber-physical system (CPS) with a physical plant, m wireless sensors, and a remote estimator, which has been widely applied in existing literature [1–3]. It is assumed that there exists a Denial-of-Service (DoS) attacker in the environment. The information CPS states that xk ∈ ℝnx may be blocked or congested by the attacker at any time. For this reason, the information received by the estimator satisfies

where 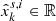 is the value of a certain state at time k. The value is measured by sensor i in real-time. s is the abbreviation of the sensor.
is the value of a certain state at time k. The value is measured by sensor i in real-time. s is the abbreviation of the sensor.
Along with DoS attacks, network transmission is also susceptible to attenuation and interference, which causes data packet dropouts. The signal-to-interference-and-noise ratio (SINR) is introduced as a way to assess the integrity of data after transmission.
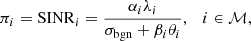
where ℳ = {1,2,…,m}. m is the number of channels. The fading channel gain of the defender or attacker for the ith channel is denoted by αi, βi > 0. The level of background noise is described by σbgn. The energy assigned by the defender or attacker to the ith channel is denoted by λi, θi ≥ 0. If the attacker does not launch DoS attacks, the SINR can be simplified to signal-to-noise ratio (SNR), which is indicated by ρi.
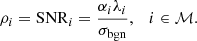
1.2. Reward function and strategy
Suppose the probability that there is only background noise in the channel is γ, and both players know the total energy of each other, which are 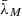 and
and  . The rewards for the defender and the attacker are given as follows
. The rewards for the defender and the attacker are given as follows
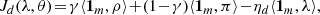
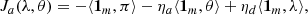
where ![$ \rho = [\rho_{1},\ldots,\rho_{m}]^{\top}, \pi = [\pi_{1},\ldots,\pi_{m}]^{\top}, \lambda = [\lambda_{1},\ldots,\lambda_{m}]^{\top}, \theta = [\theta_{1}, \ldots ,\theta_{m}]^{\top}, \mathbf{1_{m}} = [1,\ldots,1]_{1 \times m}^{\top} $](/articles/sands/full_html/2024/01/sands20230006/sands20230006-eq9.gif) and ηd, ηa refer to the cost of unit energy consumed by defender and attacker, respectively. ⟨ ⋅ ⟩ denotes the standard inner product in n-dimensional Euclidean space.
and ηd, ηa refer to the cost of unit energy consumed by defender and attacker, respectively. ⟨ ⋅ ⟩ denotes the standard inner product in n-dimensional Euclidean space.
The goal of the defender and the attacker is to maximize their reward value. Hence, strategies should be their real-time decisions on energy allocation. The strategy sets ℛd, ℛa are given for defender and attacker, respectively. 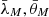 refer to the total energy available for both sides of the game.
refer to the total energy available for both sides of the game.
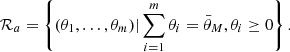
2. Main results
In the following contents, theoretical results of Stackelberg equilibrium in static Stackelberg game [5] and strategies for both defender and attacker in dynamic Stackelberg game are given.
2.1. Static game analysis
Given that both sides’ total energy is known, the following optimization problem can be solved to determine the optimal DoS attack strategy for the attacker. Theorem 1 is the theoretical conclusion reached by utilizing the Karush-Kuhn-Tucker (KKT) conditions [6].
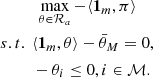
Theorem 1 Suppose that the defender’s strategy is known as λ. The optimal strategy of energy allocation obtained by the attacker to respond to the defender’s defensive scheme is
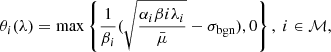
where 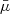 is the solution of the following equation
is the solution of the following equation
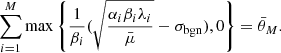
Proof. See Appendix A for details.
Meanwhile, a non-convex optimization problem can be solved to determine the defender’s best course of action. The numerical result of Stackelberg Equilibrium is proposed to be found using a self-adaptive particle swarm optimization (PSO). Appendix B contains a complete list of the steps.
Remark 1. The attack-defence model in CPS constructed in this commentary can be extended to the Stackelberg game with multiple attackers and defenders. It has been proved [7, 8] that there exist equilibrium points as long as the reward function of both sides guarantees certain convexity requirements. The procedures of proving the static equilibrium and obtaining the optimal attack strategy are similar [9]. The differences in attack strategy between work [9] and this commentary lie in the physics scene and mathematical modeling. Attackers’ unknown energy is emphasized in work [9], while the probability of launching DoS attacks is considered in this commentary.
2.2. Dynamic game
In mathematical form, the reward function for the defender is undoubtedly a linear function with respect to λ. To express it in vector form, Jd = φ⊤λ. As a result, the defender can adopt the optimal defensive strategy based on the following theorem.
Theorem 2 Given the attacker’s strategy θ, the optimal response for the defender is to allocate all of its limited energy to the channel with the maximum weight factor φi, which is the index of the maximum item in the weight factor vector. If there is not a unique index with the maximum weight factor, then the optimal response for the defender is a set of channels with equal weight factors
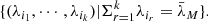
Proof. See Appendix C for details.
Based on Theorem 1 and 2, a computational algorithm can be designed for the evolution of the strategies of both attackers and defenders in a dynamic Stackelberg game.
3. Simulation results
The probability of the attacker’s existence is chosen as γ = 0.4. For simulation, consider the network parameters selected in [3], where m = 4, 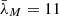 ,
, 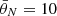 , ηa = ηd = 0.3, σbgn = 0.2, α = [0.8, 0.7, 0.6, 0.5]⊤ and β = [0.2, 0.3, 0.4, 0.5]⊤. The static equilibrium of energy allocation for both the defenders and the attackers is depicted in Figure 1a. In the dynamic game scenario, after 10 000 Monte Carlo simulations, it is found that the energy allocation pattern varies. The reward values are plotted in Figure 1b. Table 1 summarizes the optimal strategies for both defenders and attackers. It is observed that compared to the static equilibrium scenario, even if the amount of energy allocated to each channel and the resulting reward values vary, both defenders and attackers still allocate the majority of their resources to Channel 1 and Channel 2. The additional details of the simulations are included in Appendix E. To further strengthen the novelty of the proposed PSO, a set of comparative experiments is included in the supporting information, as shown in Appendix F.
, ηa = ηd = 0.3, σbgn = 0.2, α = [0.8, 0.7, 0.6, 0.5]⊤ and β = [0.2, 0.3, 0.4, 0.5]⊤. The static equilibrium of energy allocation for both the defenders and the attackers is depicted in Figure 1a. In the dynamic game scenario, after 10 000 Monte Carlo simulations, it is found that the energy allocation pattern varies. The reward values are plotted in Figure 1b. Table 1 summarizes the optimal strategies for both defenders and attackers. It is observed that compared to the static equilibrium scenario, even if the amount of energy allocated to each channel and the resulting reward values vary, both defenders and attackers still allocate the majority of their resources to Channel 1 and Channel 2. The additional details of the simulations are included in Appendix E. To further strengthen the novelty of the proposed PSO, a set of comparative experiments is included in the supporting information, as shown in Appendix F.
 |
Figure 1. Reward value of both sides. (a) Self-adaptive PSO. (b) Dynamic game |
Optimal strategy for both sides in static game and dynamic game
4. Conclusion
In this commentary, a Stackelberg game framework for a multi-channel CPS consisting of one DoS attacker and one defender is introduced. Simulation results demonstrate that both offline and online strategies demonstrate a tendency to allocate energy to specific channels. In the dynamic game setting, the defender and attacker energy allocation strategies follow a repeating pattern, with the average values approaching static equilibrium levels. Future work will focus on extending the proposed framework to investigate false data injection attacks and replay attacks.
Authors’ Contributions
Zhuping Wang provided the core idea behind this paper. Haoyu Shen was a co-author and driving force behind the creation of this commentary. Hao Zhang provided feedback and corrected errors in the text and was also a co-author. Sheng Gao contributed by verifying theoretical derivations and assisting with simulation experiments. Huaicheng Yan oversaw the completion of the commentary and provided suggestions for future research directions.
Funding
This work is supported by the National Natural Science Foundation of China (62273255, 62088101), Shanghai International Science and Technology Cooperation Project (22510712000, 21550760900), Shanghai Municipal Science and Technology Major Project (2021SHZDZX0100) and Fundamental Research Funds for the Central Universities.
Supporting Information
The supporting information is published as submitted, without typesetting or editing. The responsibility for scientific accuracy and content remains entirely with the authors. Access here
References
- Li Y, Shi L and Cheng P et al. Jamming attacks on remote state estimation in cyber-physical systems: A game-theoretic approach. IEEE Trans Autom Control 2015; 60: 2831–2836 [CrossRef] [Google Scholar]
- Li Y, Mehr AS and Chen T. Multi-sensor transmission power control for remote estimation through a sinr-based communication channel. Automatica 2019; 101: 78–86 [CrossRef] [Google Scholar]
- Liu H. SINR-based multi-channel power schedule under dos attacks: A stackelberg game approach with incomplete information. Automatica 2019; 100: 274–280 [CrossRef] [Google Scholar]
- Proakis JG and Salehi M. Digital Communications (5th ed). New York: McGraw-Hill, 2007 [Google Scholar]
- Fujiwara-Greve T. Non-cooperative Game Theory Tokyo: Springer, 2015 [CrossRef] [Google Scholar]
- Boyd SP and Vandenberghe L. Convex Optimization Cambridge: Cambridge University Press, 2004 [CrossRef] [Google Scholar]
- Fiez T, Chasnov B and Ratliff L. Implicit learning dynamics in stackelberg games: Equilibria characterization, convergence analysis, and empirical study. Proc 37th Int Conf Mach Learn (PMLR) 2020; 119: 3133–3144 [Google Scholar]
- Sherali HD. A multiple leader stackelberg model and analysis. Oper Res 1984; 32: 390–404 [CrossRef] [Google Scholar]
- Wang Z, Shen H and Zhang H, et al. Optimal DoS attack strategy for cyber-physical systems: A Stackelberg game-theoretical approach. Inf Sci 2023; 642: 119134 [CrossRef] [Google Scholar]
© The Author(s) 2024. Published by EDP Sciences and China Science Publishing & Media Ltd.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
All Tables
All Figures
|
Figure 1. Reward value of both sides. (a) Self-adaptive PSO. (b) Dynamic game |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.