Figure 7.
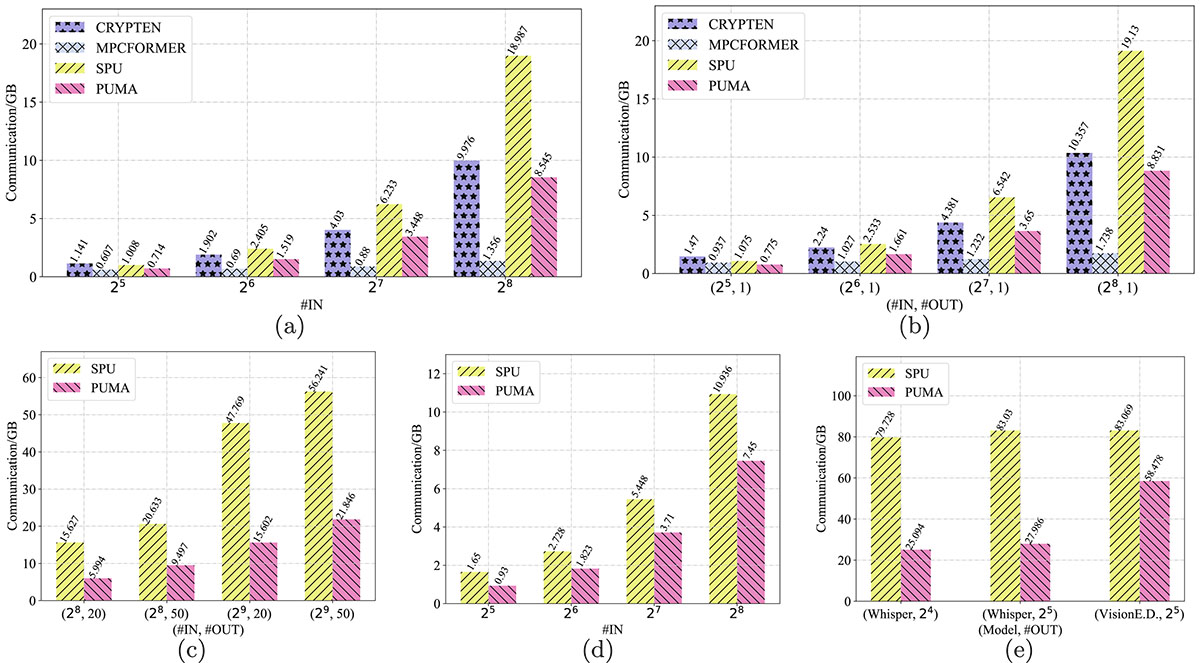
Download original image
End-to-end communication costs of Transformer models. #IN denotes the number of input tokens. MPCFORMER uses Quad approximation on top of CRYPTEN. For Whisper, the audio’s features vector is of size [1, 80, 300]. For VisionE.D., the input image is of size [1, 3, 224, 224]. For T5-Small with text translation, we use the default #OUT determined by models and omit it. Bert-Base outputs classification label and we omit its #OUT. For others, #OUT denotes the number of generated tokens. (a) Bert-Base, (b) GPT2-Base, (c) T5-Small, Summ., (d) T5-Small, Trans, (e) Whisper & VisionE.D.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.